 Seth0x41
Seth0x41إتكلمنا المرة الي فاتت عن الـ Buffers، المرة دي هنتكلم عن الـ Channels وإزاي الإتنين مع بعض هيوصلوك لأداء عالي في الـ I/O Operations.
إيه هي الـ Channels؟
الـ channel عبارة عن object بيمثل open connection مع file أو network socket أو component في application أو hardware device أو أي كيان تاني يقدر يعمل Read/Write Operations.


الـ channels بتنقل الـ data بكفاءة بين الـ byte buffers و بين الـ Resources الحقيقة الي الـ OS بيديرها زي الـ Hard disk أو ال Network card.
لو لاحظت سواء في الـ Read أو الـ Write هتلاقي إن الـ endpoints إلي بتستقبل أو بتبعت الـ data بتستخدم الـ Byte Buffers لده.
غالبًا بيكون في one-one relationship بين الـ File handle في ويندوز أو الـ File descriptor في لينكس وبين الـ channel، لما بنتعامل مع الـ channels في سياق الملفات، الـ channels غالبًا بتكون متصلة مع file descriptor مفتوح، وبالرغم من إن الـ channels تعتبر abstract أكتر من الـ file descriptor إلا انها لسه قادرة تمثل إمكانيات الـ I/O بتاعت الـ OS.
تقدر تعرف أكتر عن الـ File descriptor من الريسورس ده.
https://biriukov.dev/docs/fd-pipe-session-terminal/1-file-descriptor-and-open-file-description/
جافا بتدعم الـ channels عن الـ packages دي
java.nio.channels:
دي الـ package الي انتَ هتستخدمها يوميًا، فيها classes زي الـFileChannelوSocketChannel، هدفها هو الـ abstraction لسهولة الإستخدامjava.nio.channels.spi:
دي بقى خاصة للناس إلي بتبني الـ Java Implementation نفسه، أو بيعرفوا Selector Providers جداد، غالبًا مش هتستخدمها غير لو عايز تبني Custom Channel Implementation معقد.
كل الـ Channels عبارة عن instances من classes بتـ implement الـ interface الي اسمه java.nio.channels.Channel وإلي بيعرف الـ Methods دي:
void close():
بتقفل الـ channel دي، ولو الـ channel مقفولة أصلا فهي مش هيكون ليها تأثير، لو جه thread تاني حاول ينادي close() هيتعمله block لحد ما أول close() اتنادت تخلص، والنداءات التانية مش هيكون ليها تأثير.
الـ Method دي بترمي java.io.IOException لو حصل مشكلة في الـ I/O وبعد ما الـ channel تتقفل، اي محاولات تانية إنك تعمل I/O operations هيترميلك الـ Exception ده java.nio.channels.ClosedChannelException.
boolean isOpen():
بترجع الـ state بتاعت الـ channel إذا كان مفتوح ولا لأ، الـ method دي بترجع true لو كان مفتوح، غير كده بترجع false.
الـ Methods دي بتوضح إن في عمليتين بس مشتركتين بين كل الـ Channels، قفل الـ channel وإنك تتأكد إنها مفتوحة ولا لأ، والحقيقة ده بيطبق مبدأ الـ Interface Segregation Principle لإن الـ Channel بيمثل مجرد إتصال بس، بغض النظر عن الإتصال ده بيعمل read/write ولا لأ.
عشان تدعم الـ I/O بقى الـ channel بتـ extends عن طريق interfaces الي هما:
-
java.nio.channels.WritableByteChannel
بيعرف abstract method اسمهاint write(ByteBuffer buffer)وإلي بتكتب byte sequence من الـ Buffer للـ channel الحالي. الـ method دي بترجع عدد الـ bytes الي اتكتبت فعليًا، وبترميjava.nio.channels.NonWritableChannelExceptionلو الـ channel مكانتش مفتوحة للكتابة، وjava.nio.channels.ClosedChannelExceptionلو الـ channel مقفول، وjava.nio.channels.AsynchronousCloseExceptionلو في thread تاني قفل الـ channel اثناء الكتابة، وjava.nio.channels.ClosedByInterruptExceptionلو thread تاني interrupts الـ thread الحالي أثناء الكتابة بالتالي الـ channel هتتقفل و الـ thread الي اتعمله interrupt الـ state بتاعته هتبقىinterrupted، الـIOExceptionلو حصل أي مشكلة I/O تانية. -
java.nio.channels.ReadableByteChannel:
بيعرف abstract method اسمهاint read(ByteBuffer buffer)بتقرأ bytes من الـ channel الحالي وتحطها في الـ buffer وبترجع عدد الـ bytes الي اتقرت فعليًا، أو -1 لو مفيش bytes تانية تتقرأ، وبترميjava.nio.channels.NonReadableChannelExceptionلو الـ channel مكنش مفتوح للقراءة، وClosedChannelExceptionلو الـ channel مقفول، وAsynchronousCloseExceptionلو thread تاني قفل ال channel أثناء القراءة، وClosedByInterruptExceptionلو thrad تاني قطع الـ thread الحالي أثناء الـ reading operation بالتالي الـ channel هتتقفل والـ thread الي اتعمله interrupt الـ state بتاعته هتبقىinterruptedوالـIOExceptionلو حصل أي مشكلة I/O تانية.
تقدر تسخدم الـ instanceof operator عشان تعرف إذا كان الـ channel instance بينفذ أي interface منهم، ولإن الموضوع بيبقى رخم إنك تختبر الإتنين مع بعض، جافا وفرت interface اسمه java.nio.channels.ByteChannel وده عبارة عن marker interface فاضي بيورث من WritableByteChannel و ReadableByteChannel. لما تحب تعرف إذا كان الـ channel هي bidirectional ولا لأ، استخدم ده، لإن في الطبيعي إن الإتنين التانيين بيكونوا unidirectional سواء للقراءة أو للكتابة.
الـ channel كمان معموله extend من الـ interface الي اسمه java.nio.channels.InterruptibleChannel، الـ InterruptibleChannel بتـ describe الـ channel الي ممكن تتقفل بشكل asynchronously وممكن تبقى interrupted. الـ interface بيعمل override للـ method الي اسمها close() الموجودة في الـ Channel وبيضيف شرط إضافي للـ contract بخصوص الـ method دي، أي thread متعطل حاليًا في I/O operation في الـ channel ده هيترميله AsynchronousCloseException.
الـ channel الي بيـ implement الـ interface ده بيكون Asynchronously closeable، فلما يكون في thread متعطل في I/O operation على interruptible channel، فممكن أي thread تاني ينادي الـ close() method بتاعت الـ channel (channel.close()) وده بيخلي الـ thread المتعطل يستلم instance من الـ AsynchronousCloseException.
الـ channel الي بيـ implement الـ interface ده كمان بيكون interruptible، لما يكون في thread متعطل في I/O operation على interruptible channel، فممكن thread تاني يـ call الـ interrupt method بتاعت الـ thread المتعطل (threadA.interrupt()) عمل الموضوع ده بيخلي الـ channel يتقفل، والـ thread المتعطل يستلم instance من ClosedByInterruptException وحالة الـ interrupt بتاعت الـ thread المتعطل تبقى interrupted.
لو في Thread الـ interrupt status بتاعته مفعلة أصلا، وبيستدعي I/O operation بتعمل block على الـ channel وقتها الـ channel هتتقفل والـ thread هيستلم فورًا instance من ClosedByInterruptException، وحالة الـ interrupt بتاعته هتفضل مفعلة.
مصممي الـ NIO اختاروا إن الـ channel تتقفل لما الـ blocked thread يبقى interrupted لانهم ملحقوش يلاقوا طريقة يعالجوا بيها الـ interrupted I/O operations بنفس الاسلوب في كل أنظمة التشغيل، الطريقة الوحيدة لضمان سلوك محدد كانت هي قفل الـ channel.

تقدر تعرف الـ channel بيدعم الـ Asynchronously closeable و الـ interruption ولا لأ عن طريق الـ instanceof operator في expression زي channel instanceof InterruptibleChannel
في طريقتين عشان توصل للـ Channels
- الـ package الي اسمها
java.nio.channelsبتوفر utility class اسمه Channels بيقدم طريقتين عشان تعمل obtaining لـ channels من الـ streams. كل طريقة منهم الـ stream الأساسي بيتقفل لما الـ channel يتقفل، والـ channel ميكونش buffered:
WritableByteChannel newChannel(OutputStream outputStream)
بترجع writable byte channel للـ outputStream المٌعطى.ReadableByteChannel newChannel(InputStream inputStream)
-بترجع readable byte channel للـ inputStream المُعطى.
- في classes كتيرة من الـ classic I/O اتعدلت عشان تدعم إنشاء الـ channels، مثلا الـ
java.io.RandomAccessFileبيعرف method اسمهاFileChannel getChannel()عشان ترجع file channel، وjava.net.Socketبيعرف method اسمهاSocketChannel getChannel()عشان ترجع socket channel.
عشان الموضوع يكون أوضح، هنعمل مثال بسيط لبرنامج بيعمل echo باستخدام الـ channels.
هنستخدم الـ channels class عشان ناخد channel للـ standard input والـ output streams بعدين نستخدمه عشان ننسخ الـ bytes من الـ input channel للـ output channel.
هنكتب الـ main method في الأول، وهنعرف فيها الـ channels بتاعتنا
هنستخدم الـ ReadableByteChannel للـ System.in وده بيمثل الـ input وهنستخدم WritableByteChannel للـ System.out وده للـ output، وهننادي على method هنعملها اسمها copy مسؤولة انها تنقل الداتا.
public static void main(String[] args) {
try (ReadableByteChannel src = Channels.newChannel(System.in);
WritableByteChannel dest = Channels.newChannel(System.out)) {
try {
copy(src, dest);
} catch (IOException e) {
System.err.println("I/O Error: " + e.getMessage());
}
} catch (IOException e) {
e.printStackTrace();
}
}
دلوقتي هنعمل الـ implementation للـ copy method.
static void copy(ReadableByteChannel src , WritableByteChannel dest) throws IOException{
ByteBuffer buffer = ByteBuffer.allocateDirect(2048);
while (src.read(buffer) != -1){
buffer.flip();
dest.write(buffer);
buffer.compact();
}
buffer.flip();
while (buffer.hasRemaining())
dest.write(buffer);
}
الميثود دي هتاخد الـ channels بتاعتنا، بعدين هتحجز Direct buffer، اتكلمنا عنه وعن ال buffers بالتفصيل قبل كده هنا، بعدين هتدخل جوه الـ while loop دي عشان تقرأ الداتا الي جاية من الـ source channel لحد الأخر (لما الـ read ترجع -1 ) بعدين هتعمل flip للـ buffer عشان نقدر نسحب منه البيانات دي، بعدها هنكتبها في الـ dest channel عن طريق dest.write(buffer) بعد ما نكتبها هنعمل compact عشان نضمن إن لو في داتا فاضلة لسه في ال buffer تترتب تاني، بعد ما نخرج من ال while loop هنعمل flip تاني ونشوف لو في داتا فاضلة نتيجة ال compact الي اتعمل ترجع.
قبل ما نجرب البرنامج، تعالى نعمل implementation لطريقة تانية لل copy، هنسميها copyAlt()
static void copyAlt(ReadableByteChannel src, WritableByteChannel dest) throws IOException{
ByteBuffer buffer = ByteBuffer.allocateDirect(2048);
while (src.read(buffer) != -1) {
buffer.flip();
while(buffer.hasRemaining())
dest.write(buffer);
buffer.clear();
}
}
حجزنا هنا نفس الـ buffer و وبنحط الداتا جوه الـ buffer من خلال ال loop دي زي ما عملنا في ال method الي فاتت، وعملنا flip برضو عشان نعرف نسحب الداتا، لكن في اختلاف هنا، حاول تلاحظه بنفسك الأول.
لو أخدت بالك هنا فـ الطريقة الي بنتعامل بيها مع الداتا الي فاضلة هنا مختلفة عن الطريقة الأولى، الأول كان ممكن اتسامح في إن في داتا انا مأخدتهاش، وقررت إني هعمل compact وأهندل الداتا الي فاضلة دي بره الـ loop، لكن هنا الموضوع مختلف، هنا بيضمن إن كل حاجة اتعملها write في ال dest وال buffer فضي قبل ما يخرج، الحقيقة إن عملية الـ compact دي Expensive لإنها بتعمل System.arraycopy داخليًا عشان تنقل الـ bytes المتبقية من آخر الـ buffer لأوله، وده استهلاك للـ CPU والـ memory bandwidth، لكن المميز فيها هو إنها None-Blocking ready، خلينا نتخيل سيناريو إن في سيرفر بيبعتك داتا من هارد ديسك عنده، لكن النت عندك مش أحسن حاجة، في الأول احنا قرأنا الـ 100 بايت من السيرفر، وال buffer دلوقتي مليان على الأخر، انتَ استقبلت 5 بايت بس من الـ buffer ده لإن النت عندك مش كويس، الطبيعي لو بنستخدم الـ copyAlt method الـ thread هيفضل blocked جوه ال loop مستني الـ buffer يخلص، فكل شوية هيلف ويبعت 0 بايت، لكن في الـ copy الي هيحصل إن طالما في 5 اتقرأوا فـ هيعمل compact للـ 95 الباقيين يحطهم في الأول، ويقول للـ thread املالي الـ 5 الفاضيين دول، فمش هيقف يستنى الشبكة تهندل ده. الطريقة بتاعت الـ copyAt الميزة الي فيها انها أسرع لإنك بمجرد ما هتخلص هتعمل buffer.clear() وده لإنك مجرد بترجع تظبط الـ pointers زي الـ position وال limit بس من غير ما تمسح داتا فعليًا او تنقلها زي ما اتكلمنا قبل كده في الـ buffers، لكن العيوب زي ما شوفنا انها هتفضل رهينة حاجة زي النتورك زي المثال الي اتكلمنا عنه، عشان كده الاستخدام الأمثل لده هو الـ Blocking File I/O وعدم استخدام الـ compact هيكون أكفأ لإن اساسًا الكتابة على الديسك غالبًا ما بتكون سريعة، لكن استخدم الـ compact هيكون أحسن لو بتتعامل مع حاجة زي الـ network socket.
تعالى بقى نجرب الكود بتاعنا ده:
java Main.java
ده هيفتح معاك echo، بمجرد ما تكتب حاجة هيرد عليك تاني بنفس الحاجة، ممكن كمان تعمل
java Main.java < testfile > testfile.bak
ده هينسخ محتويات الـ testfile لـ testfile.bak، لو جربت بقى تغير الـ copy لـ copyAlt هيحصل نفس الحاجة.
خطوة أعمق للـ Channels
الكلام إلي فات كان عن الـ channel interface عشان تاخد فكرة عن الـ channels، تعالى بقى نشوف حاجات زي الـ scatter/gather I/O، والـ file channels، والـ socket channels، والـ pipes.
الـ Scatter/Gather I/O
الـ channels بتوفر القدرة إنك تنفذ I/O operation واحدة على كذا buffer، الميزة دي معروفة بإسم scatter/gather I/O أو الـ vectored I/O.
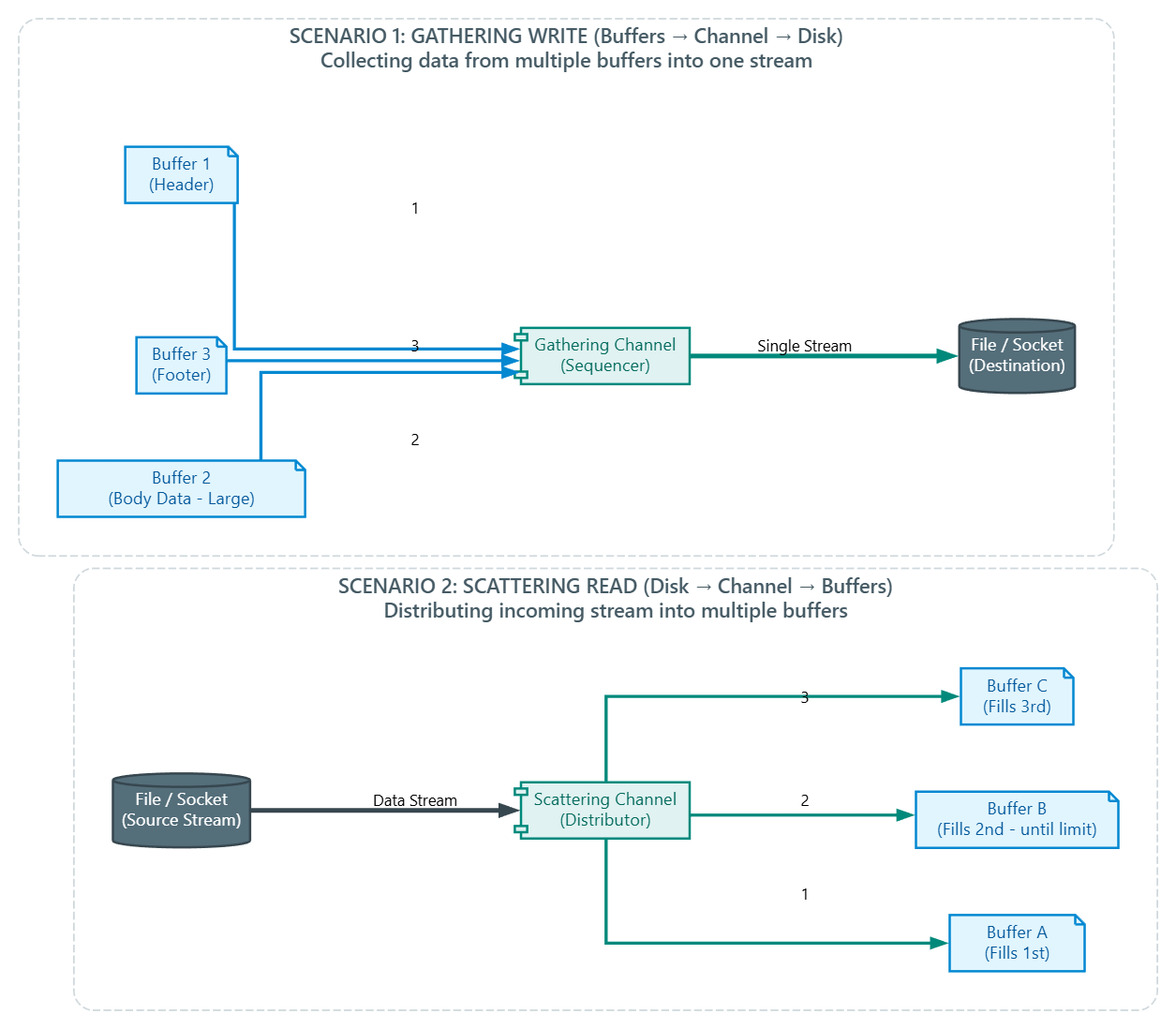
في سياق الـ writes operations محتويات كذا buffer بيتم تجميعها (gathered) بالترتيب بعدين تتبعت من خلال channel للـ Destination زي ماهو واضح في السيناريو الأول في الصورة، الـ buffers دي مش شرط يكون ليها نفس الـ capacity.
في سياق الـ read operations، محتويات الـ channel بيتم توزيعها (scattered) على كذا buffer بالترتيب، كل buffer بيتملي لحد الـ limit بتاعه لحد ما الـ channel يفضى أو لحد ما مساحة الـ buffers كلها تخلص.
الـ OS الحديثة بتوفر APIs بتدعم الـ vectored I/O عشان تقلل أو تلغي الـ system calls او نسخ الـ buffers، بالتالي الأداء يتحسن، فمثلًا Win32/Win64 APIs بتوفر functions زي
ReadFileScatter()وWriteFileGather()للغرض ده.
جافا بتوفر interface اسمه java.nio.channels.ScatteringByteChannel عشان تدعم الـ scattering و interface تاني للـ gathering اسمه java.nio.channels.GatheringByteChannel.
الـ ScatteringByteChannel بيقدم الـ methods دي:
long read(ByteBuffer[] buffers, int offset, int length)long read(ByteBuffer[] buffers)
و الـGatheringByteChanneبيقدم الـ methods دي:long write(ByteBuffer[] buffers, int offset, int length)long write(ByteBuffer[] buffers)
أولread()method وأولwrite()method بياخدوا منك Array من الـ buffers وبيسمحولك تحدد أول buffer الي هتقرأ منه أو تكتب فيه عن طريق إنك تبعت offset بـ index الـ buffer ده، والـ length بيحدد هتستخدم كام buffer من بعد نقطة البداية دي.
تانيread()وتانيwrite()بيقروا ويكتبوا في كل الـ buffers بالترتيب.
تعالى نعمل مثال ونلعب بترتيب الـ buffers جوه الـ channels شوية.
public static void main(String[] args) throws IOException {
ScatteringByteChannel src ;
FileInputStream fis = new FileInputStream("input.dat");
src = (ScatteringByteChannel) Channels.newChannel(fis);
ByteBuffer buffer1 = ByteBuffer.allocateDirect(5);
ByteBuffer buffer2 = ByteBuffer.allocateDirect(3);
ByteBuffer[] buffers = {buffer1,buffer2};
src.read(buffers);
buffer1.flip();
while (buffer1.hasRemaining())
System.out.println(buffer1.get());
buffer2.flip();
while (buffer2.hasRemaining())
System.out.println(buffer2.get());
}
إلي بيحصل هنا إننا بنعمل channel من نوع ScatteringByteChannel وبنعمل FileInputStream بتاخد الملف الي اسمه input.dat، بعدين بنعمل channel على الـ stream ده Channels.newChannel(fis) وبنعمله casting للـ ScatteringByteChannel، فكده الـ ScatteringByteChannel بقى جاهز معانا اننا نستخدمه.
بعد كده بنينا الـ buffers بتوعنا buffer1 و buffer2 الي هيشيلوا الداتا، وعملنا array من الـ buffers دي ByteBuffer[]، دلوقتي نقدر ببساطة نحط الداتا من الملف ده جوه الـ buffers دي بإستخدام read الي بيقدمها الـ ScatteringByteChannel الي اتكلمنا عنها، فـ هياخد الداتا ويوزعهم على ال buffers الي عندنا.
هنعمل flip للـ buffers بتاعتنا عشان نقرأ منها الي اتكتب جواها وهنطبعه دلوقتي في الـ console.
اعمل ملف اسمه input.dat وحط فيه النص ده:
12345abcdefg
هتلاقي الـ output بتاعك كده، دي الـ ASCII Codes الخاصة بالـ input.
49
50
51
52
53
97
98
99
تعالى نعمل rewind للـ buffers عشان نرجع الـ position للصفر ونقرأ الداتا منهم تاني، المرة دي هنستخدم الـ GatheringByteChannel والـ FileOutputStream عشان نقرأ الداتا من ال buffers ونكتبها جوه file، هنضيف على الكود الي فات الجزء ده :
buffer1.rewind();
buffer2.rewind();
GatheringByteChannel dest;
FileOutputStream fos = new FileOutputStream("output.dat");
dest = (GatheringByteChannel) Channels.newChannel(fos);
dest.write(buffers);
لو جربت تشغل الـ code بعد ما تضيف السطور دي هتلاقي إتعمل ملف اسمه output.dat واتكتب فيه 12345abc بس، والـ defg الي كانت موجودة مع الـ input اختفوا، ده ليه؟ ده عشان حجم الـ buffers مش أكتر، احنا عملنا اتنين، واحد يشيل 5 وده الي شال ال 5 أرقام الأولانية، وواحد يشيل 3 وده الي شال bytes الـ 3 حروف الي خرجوا معانا.
بما اننا قادرين نتحكم في الـ buffers كده، المفروض اننا لو غيرنا ترتيب الـ array دي، ترتيب الداتا يختلف، مش كده؟ تعالى نضيف السطرين دول قبل الـ dest.write
buffers[0] = buffer2;
buffers[1] = buffer1;
لو عملت السطرين دول، هتلاقي ان الناتج بقى abc12345 معنى كده انه كان بيملاهم بالترتيب فعلا لحد ما يخلصوا، ومعنى كده برضو ان الـ buffer التاني كان شايل الحروف بس زي ما توقعنا.
الـ File Channels
في method جوه الـ java.io.RandomAccessFile اسمها File Channel getChannel() وإلي بترجع instance من الـ File Channel الي بيوصف open connection بـ file. وكمان نفس الـ method موجودة في الـ FileInputStream والـ FileOutputStream، في مقابل ده java.io.FileReader والـ java.io.FileWriter مبيوفروش طريقة عشان تقدر تاخد file channel.
الـ File Channels الي بترجع من الـ
FileInputStreamبتكونread-onlyوالي بترجع منFileOutputStreamبتكونwrite-onlyفمينفعش تعكس الـ operations عليهم عشان هترمي exceptions.
الـ java.nio.channels.FileChannel abstract class بيوصف الـ file channel، ولإن الـ class ده بيـ implement الـ InterruptibleChannel, ByteChannel, GatheringByteChannel, ScatteringByteChannel interfaces فـ الـ File channels بتكون interruptible وكمان تقدر تقرأ منها أو تكتب فيها وتعمل عليها scatter/gather I/O وإلخ. وعلى عكس الـ Buffers الي مش thread-safe فـ الـ File channels تعتبر thread-safe.
الـ File Channels بتحافظ على الـ current position جوه الملف، وبتسمحلك تعرف وتغير المكان ده، وكمان تقدر تـ request ان الـ cached data تترحل بشكل إجباري للـ disk، وكمان تقدر تقرأ او تكتب أي محتوى في الملف، وتعرف حجم الملف المرتبط بالـ channel وتعمل truncate ليه، وتعمل كمان lock للملف كله او جزء منه، وتعمل memory-mapped file I/O، وتنقل الداتا مباشرتًا لـ channel تاني بطريقة ممكن الـ OS يعملها optimization.
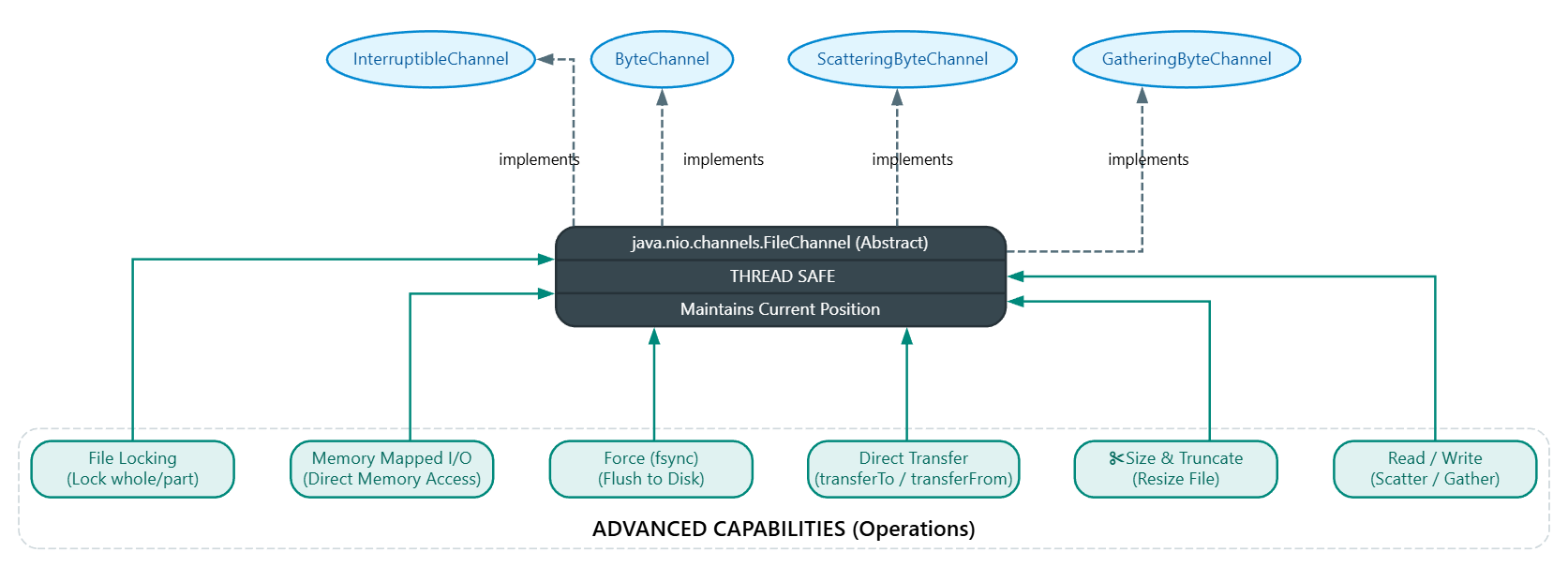
%% دي الـ Methods بتاعت الـ FileChannel: %%
FileChannel:
void force(boolean metadata):
بـ Force إن كل الـ updates على الي حصلت على الـ channels دي تتكتب على الـ storage device، لما الـ method دي بتـ returns ده بيـ guarantee ان كل التعديلات الي اتعملت على الملف المرتبط بالـ channel ده اتعملت فعلا لو الملف موجود على internal storage، لكن لو كان الملف على مش موجود عندك وموجود على network file system مثلا فوقتها مش هتقدر تتأكد إن التعديلات اتعملت فعلا.
قيمة الـ metadata بتحدد إذا كان الـ update لازم يشمل الـ metadata بتاعت الملف ولا لأ زي أخر وقت اتعدل فيه أو أخر access حصل للملف، حجم الملف، وصلاحياته، وإلخ، فلو كانت true هيشمل ده، والعكس لو false.
في ملحوظة هنا مهمة، انتَ لو عملت true والملحف مفتوح read-only، فـ انتَ برغم إنك معدلتش الداتا ف بالتالي المفروض إن force() متستخدمش أي write operation، لكن الحقيقة ان مش ده الوضع هنا، لإنك بمجرد ما فتحت الملف فـ انتَ عدلت في ال Last Access Time وده محتاج يتكتب في الـ Inode فـ الـ OS هيعمل Disk Write Operation عشان يعدل ال Inode بالتغيير ده، على عكس لو بعتلها false فـ انتَ كده كده مش مهتم بالـ metadata.
الـ method دي بترمي ClosedChannelException لو الـ channel مقفول، وبترمي IOException لو حصل أي I/O error تاني.
long position():
بترجع الـ current file position الي الـ channel محافظ عليه، وطبعًا zero-based.
الـ method دي بترمي ClosedChannelException لو الـ File channel مقفول و IOException لو حصل أي I/O error تاني.
FileChannel position(long newPosition):
الـ method دي بتغير الـ position للـ file channel للـ newPosition، الـ newPosition هو عدد الـ bytes محسوب من بداية الملف، الـ position مينفعش يبقى قيمة سالبة، ممكن يبقى قيمة أكبر من حجم الملف الحالي، وقتها محاولات القراءة هترجع End Of File - EOF لإن منطقيًا مفيش داتا في المكان ده عشان تقرأها، لكن لو قررت الكتابة فـ الكتابة هتنجح، بس هتملى الـ bytes الي بين نهاية الملف والمكان الي كتبت فيه بـ unspecified bytes، نظام التشغيل بيعتبر المنطقة دي hole وغالبًا بيحط فيها zeros، وفي file systems زي NTFS أو ext4 الـ OS مبيحجزش مساحة حقيقية على ال disk لل hole دي، بيعلم بس انها فاضية عشان يوفر مساحة.
الـ method دي بترمي java.lang.IllegalArgumentException لو الـ offset سالب، و ClosedChannelException لو الـ file channel مقفول، و IOException لو حصل أي I/O error تاني.
int read(ByteBuffer buffer):
بتقرأ الـ bytes من الـ file channel دي وتحطها في الـ buffer الي بعتهولها.
اقصى عدد من الـ bytes هيتقرأ هو عدد الـ bytes الفاضلة في الـ buffer وقت ما ناديت الـ method، والـ bytes هتتنسخ في الـ buffer بداية من الـ current position بتاع الـ buffer. الـ call ممكن يحصله block لما يكون في threads تانية بتحاول تقرأ من نفس الـ channel. ولما تخلص، الـ position بتاع الـ buffer مش بيتغير والـ method بترجع عدد الـ bytes الي اتقرت فعلا وبترمي الـ exceptions الي اتكلمنا عنها قبل كده في الـ ReadableByteChannel.
int read(ByteBuffer dst, long position):
زي الـ method الي فاتت، بس الـ bytes بتتقرأ من بداية الـ position الي مبعوت، وبترمي IllegalArgumentException لو الـ position سالب.
long size():
بترجع حجم الملف المرتبط بالـ file channel دي، الـ method دي بترمي ClosedChannelException لو الـ file channel مقفول و IOException لو حصل اي I/O error تاني.
FileChannel truncate(long size):
بتعمل truncate للملف المربوط بالـ file channel دي لحد الـ size المبعوت، أي bytes بعد الـ size المبعوت بتتحذف من الملف، لو مفيش bytes بعد الـ size، محتويات الملف مبتتغيرش.
لو الـ current file position أكبر من ال size بيتعمله set للـ size.
int write(ByteBuffer buffer):
بتكتب sequence من ال bytes للـ file channel ده من الـ given buffer، الـ bytes بتتكتب بداية من ال current file position بتاع الـ channel إلا لو كان الـ channel في الـ append mode، في الحالة دي الـ position بيتحرك الأول لأخر الملف. لما بتكتب الملف بيكبر (عند الضرورة) عشان يستوعب الـ bytes دي، بعدين الـ file position بيتحدث بعدد الـ bytes الي اتكتبت فعليًا، غير كده الـ method دي بتتصرف بالظبط زي ماهو specified في الـ WritableByteChannel interface، الـ method بترجع عدد الـ bytes الي اتكتبت فعليًا وبترمي نفس الـ exceptions الي اتكلمنا عنها قبل كده في الـ WritableByteChannel.
int write(ByteBuffer src, long position):
شبه الـ method الي فاتت، بس الـ bytes بتتكتب بداية من الـ file position المبعوت، وبيترمي IllegalArgumentException لو الـ position سالب.
الـ force(boolean)method بتحقق الـ durability عن طريق إنها بتضمن إن كل التغييرات الي اتعملت على ملف موجودة في الـ local file system من وقت آخر مرة الـ method دي اتنادت فيها. الميزة دي مهمة للـcritical tasks زي الـ transaction processing الي لازم تحافظ فيها على سلامة البيانات وتضمن إسترجاعها بشكل موثوق، لكن زي ما قولنا إن الضمان ده مبينطبقش على الـ remote file systems.
مثال على استخدام الـ File Channels:
public static void main(String[] args) throws IOException {
RandomAccessFile raf = new RandomAccessFile("test","rw");
FileChannel fc = raf.getChannel();
long pos = fc.position();
System.out.println("Position = " + pos);
System.out.println("size: " + fc.size());
}
الي نعمله هنا اننا عملنا instance من الـ RandomAccessFile على لـ file اسمه test وخلينا الـ mode بتاعه rw عشان نقدر نقرأ ونكتب فيه، الملف لو مش موجود هيعمل ملف جديد.
عملنا channel على الـ RandomAccessFile ده، وعملنا متغير اسمه pos هيتحط فيه الـ current position بتاع الـ channel ومجرد هنطبع الـ pos ده والـ size بتاع الـ channel قبل ما نعمل اي حاجة. المتوقع ان الـ result تبقى كده
Position = 0
size: 0
تعالى نحاول نكتب جملة في ال file ده
String msg = "This is a test message.";
ByteBuffer buffer = ByteBuffer.allocateDirect(msg.length()*2);
buffer.asCharBuffer().put(msg);
fc.write(buffer);
fc.force(true);
System.out.println("Position = " + fc.position());
System.out.println("size: " + fc.size());
هنا احنا عملنا msg عادية، وعملنا buffer وحجزناله مساحة حجمها طول المسدج دي مرتين.
وحطينا الـ msg دي في الـ buffer وخلينا الـ File channel تكتبها في الـ buffer واستخدمنا force(true) عشان نجبره يكتب الداتا على ال disk، بعدين هنطبع الـ position بتاع الـ file Channel عشان نشوف الـ position اتغير ولا لأ، وهو فين دلوقتي.
متنساش تمسح الفايل القديم.
الـ output مفروض يكون كده:
Position = 0
size: 0
Position = 46
size: 46
وهتلاقي ان الـ msg اتكتبت في ملف الـ test، لو عايز تقرأها عن طريق الـ buffers:
buffer.clear();
fc.position(pos);
fc.read(buffer);
buffer.flip();
while (buffer.hasRemaining())
System.out.print(buffer.getChar());
هنعمل clear للـ buffer عشان ننضفه، بعدين هنغير الـ position بتاع الـ File channel لصفر تاني، بعدين هنقرأ من الملف ونحط الداتا في الـ buffer، ونعمل flip عشان نقرأ منه، والـ while loop الي استخدمناه كتير عشان نقرأ الداتا من ال buffer.
لو مسحت الـ test file وشغلت الكود من الأول الـ result هتبقى كده
Position = 0
size: 0
Position = 46
size: 46
Position = 0
This is a test message.
ولو شغلته والملف اوريدي موجود هتبقى كده
Position = 0
size: 46
Position = 46
size: 46
Position = 0
This is a test message.
الـ Locking Files
القدرة إنك تعمل lock على الملف كله أو جزء منه مكانتش موجودة في Java لحد ما ظهرت في Java 1.4، القدرة دي بتسمح للـ JVM process انها تمنع الـ processes التانية من انها تـ access الملف كله او جزء منه لحد ما تخلص التعامل مع الملف او الجزء ده.
رغم إن الملف ممكن يتقفل كله، لكن الأحسن بيكون انك تقفل منطقة أصغر، على سبيل المثال في الـ database management systems بيقفلوا صفوف معينة في جدول بيتعملها update بدل ما يقفلوا الجدول كله، عشان الـ read requests تقدر تتنفذ، وده بيحسن الـ throughput.
الـ locks المرتبطة بالملفات اسمها File Locks كل file lock بيبدأ من مكان byte معين في الملف، وبيكون ليه طول محدد من المكان ده بالـ bytes برضو والإتنين سوا بيحددوا المنطقة الي هيتعملها lock، الـ file locks بتخلي الـ processes تنسق الـ access لمناطق مختلفة في الملف.
فيه نوعين من الـ File Locks، الأول exclusive والتاني shared.
الـ exclusive بيدي لـ writer process واحدة بس access لمنطقة في الـ region وبيمنع أي Lock Files تانية انها تطبق في نفس الوقت على الـ region دي، الهدف من الموضوع ده الـ writing، يعني لو عندك Process A معاها Exclusive Lock على ملف، فمستحيل على أي Process تاني تاخدExclusive Lock عشان محدش يكتب فوقها، ومستحيل أي process تاني تاخد shared lock عشان محدش يقرأ داتا ناقصة وهي لسه بتكتب.
الـ shared lock بيدي access لواحدة من كذا writer processes لنفس الـ region في الملف، مش بيمنع الـ shared locks التانية بس بيمنع تطبيق الـ exclusive lock في نفس الوقت على المنطقة دي، يعني لو عندك process A معاها shared lock، عادي جدًا ان process B و Process C ياخدوا shared lock في نفس الوقت ويقرأوا سوا، لكن ممنوع ان أي حد ياخد Exclusive Lock طول ما فيه ولو واحد بس معاه Shared Lock، الموضوع شبه شاشات العرض في الشارع، ممكن ناس كتيرة تقف تتفرج (Read) في نفس الوقت عادي، لكن مش المفروض إن في حد يجي يغير مكان الشاشة أو يطفيها أو يهدها (Write) طول ما في ناس بتتفرج.
الـ exclusive و shared locks بيستخدموا عادة في السيناريوهات اللي فيها ملف مشترك بيتقرأ كتير وبيتم تحديثه قليل، . الـ process اللي محتاجة تقرأ من الملف بتاخد shared lock للملف كله أو للمنطقة المطلوبة، process تانية محتاجة تقرأ برضه من الملف فبتاخد shared lock للمنطقة المطلوبةهي كمان، العمليتين يقدروا يقرأوا الملف من غير ما يتدخلوا في شغل بعض. افترض إن فيه عملية تالتة عايزة تعمل write، عشان تعمل كده، هتحتاج تطلب exclusive lock، الـ process دي هتتعطل لحد ما كل الـ exclusive أو shared locks اللي بتتقاطع مع الـ region بتاعتها تتفك.
بمجرد ما الـ exclusive lock يُمنح لـupdater process، أي reader process تطلب shared lock هيتعملها block لحد ما الـ exclusive lock يبقى released. الـ Updater process تقدر بعد كده تـ update الملف من غير ما الـreader processes تشوف بيانات غير متسقة.
في حاجتين لازم تخلي بالك منهم وانتَ بتتعامل مع الـ File locks:
1- أوقات الـ OS مبيكونش بيدعم الـ shared locks، فلما تطلب shared lock ده بيتحول لـexclusive lock وبرغم إن الـ correctness مضمونة، لكن الأداء ممكن يتأثر.
2- الـ locks بتطبق على أساس الملف مش على أساس الـ threads او الـ channels، ف لو في أكتر من thread شغالين على نفس الـ JVM وطلبوا عن طريق channels مختلفة exclusive lock لنفس المنطقة في الملف، هياخدوا access عادي، لكن لو الـ threads شغالين على JVMs مختلفة، الـ thread التاني هيتعمله block. الـ JVM بيتم التعامل معاه على نظام التشغيل على اساس انه process واحدة، جواها ثريد أو اتنين أو عشرة هو مش مهتم بده في سياق الـ File locking، ف لما تطلب exclusive lock على ملف هو هيشوف ان ال process دي طلبت الملف ده، لو في JVM تاني شغال بـ process ID مختلف وحاول يطلب lock على نفس الملف الـ OS هيمنعه. لكن لو كان thread او channel ففي الأول والأخر دول موجودين جوه الـ JVM بتاعك الي تم منحه حق الوصول قبل كده، ف انتَ عليك الدور إنك تنظم الـ synchronization على المستوى ده.
الـ FileChannel بتعرف 4 طرق عشان تعمل exclusive و shared locks:
- الـ
FileLock lock(): بتعمل exclusive lock على الملف المرتبط بالـ File channel ده، الـ convenience method دي بتُكافئ تنفيذ
fileChannel.lock(0L, Long.MAX_VALUE, false);
الـ method دي بترجع object منjava.nio.channels.FileLockبيمثل الـ locked region.
بترميClosedChannelExceptionلو الـ file channel مقفول، وNonWritableChannelExceptionلو الـ channel مش مفتوح للكتابة، وOverlappingFileLockExceptionلو في قفل بيتقاطع مع المنطقة المطلوبة ممسوك بالفعل من الـ JVM ده، أو لو في thread تاني blocked فعلا في الـ method دي وبيحاول يـ lock منطقة متقاطعة في نفس الملف، وبيرميjava.nio.channels.FileLockInterruptionExceptionلو الـ thread الي بينادي اتعمله block وهو مستني ياخد ال lock. وبيرميAsynchronousCloseExceptionلو ال channel اتقفل والـ thread الي بينادي مستني ياخد الـ lock والـIOExceptionلو حصل أي مشكلة تانية وقت ما بتطلب ال lock.
FileLock lock(long position, long size, boolean shared)
الـ method دي شبه الي فاتت بس بتحاول تاخد lock لمنطقة معينة في ملف الـ channel ده، بتحدد المنطقة عن طريق انك بتبعت ال size وال position بقيم موجبة، وبتبعت true للـ shared عشان تطلب ال shared lock و false لل exclusive lock.
FileLock tryLock()
بتحاول تاخد exclusive lock على ال file المرتبط بال file channel من غير ما يحصلها blocking. الـ convenience method دي بتكافئ fileChannel.tryLock(0L, Long.MAX_VALUE, false).
الميثود دي بترجع FileLock object بيمثل المنطقة المقفولة، او null لو القفل ده هيتقاطع مع exclusive lock موجود فعلا في process تانية للـ OS. بترمي ClosedChannelException لو الـ file channel مقفول و OverlappingFileLockException لو في lock بيتقاطع مع ال region المطلوبة ممسوك من ال JVM ده أو لو في thread تاني متعطل فعلا في ال method دي وبيحاول يـ lock منطقة متقاطعة، و IOException لو حصل أي I/O error تاني وقت ما بتطلب ال lock.
FileLock tryLock(long position, long size, boolean shared)
الـ method دي شبه الي فاتت بس بتحاول تاخد lock على منطقة معينة في ال channel ده.
الـ lock() methods بتجبر ال thread انه يتعمله block لو ال desired region اوريدي locked، ومبيتحركش غير لما ال lock يتفك إلا لو الطرفين طالبين shared lock، بيعدي عادي.
بينما الـ tryLock() methods بترجع فورًا null لما ال lock يتقاطع مع exclusive lock عشان تعرفك ان المحاولة فشلت والبرنامج بيكمل عادي.
كل ال methods بترجع FileLock instance والي بتـ encapsulate locked region في ال file.
الـ methods بتاعت الـ FileLock:
FileChannel channel()
بترجع الـ File channel الي الـ lock ده اتجاب من خلال ملفه، أو null لو الـ lock مكانش عن طريق file channel.void close()
بتنادي الـrelease()method عشان تفك الـ lock.boolean isShared()
بترجع true عشان تحدد لو كان الـ lock ده valid و false لو لأ، الـ lock بيفضل valid لحد ما يتعمله release أو الـ file channel المرتبط بيه يتعمله lock.boolean overlaps(long position, long size)
بترجع true او false عشان تحدد لو الـ lock region دي بتتقاطع مع الـ range المبعوتة في ال parameters ولا لأ.long position()
بترجع الـ position جوه الـ file لأول byte في الـ locked region. الـ locked region مش لازم تكون جوه الملف أو حتى بتتقاطع معاه، ممكن القيمة الي ال method دي بترجعها تكون أكبر من حجم الملف الحالي.void release()
بتفك الـ lock، لو الـ lock object ده valid ف لما بتنادي على ال method دي بيفك الـ lock وبيخلي ال object مش valid بينما لو الـ lock object مكانش valid ف لما بتنادي عليها مش هيكون ليها أي تأثير.long size()
بترجع طول الـ file lock بالـ bytes.String toString()
بترجع string بيوصف الـ Range والـ type و الـ validity للـ lock ده.
الـ FileLock instance بيكون مرتبط بالـ FileChannel instance بس الـ File lock الي بيمثله الـ FileLock instance بيتربط بالملف الأساسي مش بالـ File cannel.
خلي بالك وانتَ بتتعامل مع ال locks عشان ممكن ينتهي بيك الحال في مشاكل كتيرة زي ال deadlock، عشان كده فكر دايمًا وانتَ بتشتغل انك تـ release الـ file lock، النمط الي لازم يكون في دماغك دايمًا انك تعمل
FileLock lock = fileChannel.lock();
try{
// logic with file channel
}
catch (IOException ioe){
// handle the exception
finally{
lock.release();
}
Mapping Files into Memory
الـ File channel بيعرف map() method بتسمحلك تعمل virtual memory mapping بين منطقة في ملف مفتوح وبين java.nio.MappedByteBuffer instance بيـ wrap نفسه حوالين الـ region دي.
آلية الربط دي بتوفر طريقة فعالة عشان تـ access الملفات لإن مفيش time-consuming system calls هتكون مطلوبة عشان تنفذ الـ I/O.
MappedByteBuffer map(FileChannel.MapMode mode, long position, long size)
دي الـ map() method، الـ mode parameter بيحدد الـ mapping mode وبياخد واحد من الـ constants المتعرفة في الـ FileChannel.MapMode enumerated type:
1- READ_ONLY
أي محاولة لتعديل الـ buffer هترمي java.nio.ReadOnlyBufferException
2-READ_WRITE
التغييرات الي بتتعمل على ال buffer الناتج هتنتقل في النهاية للملف، وممكن متكونش visible للبرامج التانية الي معمولها mapped مع نفس الملف.
3- PRIVATE
التغييرات الي بتتعمل على ال buffer الناتج مش هتنتقل للملف، ومش هتكون visible للبرامج التانية الي معمولها mapped مع نفس الملف، بدل كده التغييرات دي هتتسبب في إنشاء copies من الـ modified portions في الـ buffer. التغييرات دي بتضيع لما الـ buffer يتم مسحه عن طريق الـ garbage collector.
الـ specified mapping mode بيُقيد بالـ access permissions بتاعت FileChannel object الي نادى الـ method، فمثلاً لو الـ file channel اتفتح كـ read-only وانت طلبت READ_WRITE mode الـ map هترمي NonWritableChannelException لانها مش هتقدر تكتب في الـ file channel، وبنفس المنطق الـ NonReadableChannelException بتترمي لما الـ channel يتفتح كـ write only وانت تطلب read only mode (تقدر تطلب READ_ONLY لـ file channel مفتوح كـ Read-Write channel).
تقدر تستخدم الـ method الي اسمها
isReadOnly()بتاعت الـMappedByteBufferعشان تعرف إذا كنت تقدر تـ modify في الـ mapped file ولا لأ.
الـ Position والـ size parameters بيحددوا الـ start والـ extent للـ mapped region، فالمفروض انهم يكونوا non-negative والـ size قيمته متزيدش عن الـ Integer.Max_Value.
الـ specified range مش لازم يزيد عن حجم الملف لإن الملف هيكبر عشان يستوعب الـ range ده، فلو بعت Integer.Max_Value للـ size، الملف هيكبر لأكتر من اتنين جيجابايت، وكمان بالنسبة لـ read-only mapping الـ map() غالبًا هترمي IOException.
الـ MappedByteBuffer object الي بيرجع بيتصرف زي الـ Memory-mapped buffer بس الـ content بتاعه stored في file. لما بتنادي get() على الـ object ده بتاخد على الـ current content للملف، حتى لو الـ content ده اتعدل عن طريق external program، وبنفس المنطق لما يكون عندك write permission وتنادي على put() ده بيـ update الـ file والـ changes بتكون available للـ external programs.
لإن الـ mapped byte buffers هي direct byte buffers فالـ memory space المخصصة ليها بتكون موجودة بره الـ heap بتاع الـ JVM.
MappedByteBuffer buffer = fileChannel.map(FileChannel.MapMode.READ_ONLY, 50, 100);
الكود ده بيـ map subrange من الـ location 50 لحد الـ location 149 من الملف الموصوف بالـ fileChannel، في المقابل الكود الجاي ده بيـ map الملف كله
MappedByteBuffer buffer =
fileChannel.map(FileChannel.MapMode.READ_ONLY, 0, fileChannel.size());
بمجرد ما بيتعمل Mapping بيفضل موجود لحد ما الـ MappedByteBuffer object يتمسح عن طريق الـ garbage collector، أو الأبلكيشن يتقفل. ولإن الـ mapped byte buffer مش connected بالـ file channel الي اتعمل من خلاله، فالـ mapping مش بيتدمر لما الـ file channel يتقفل.
الـ MappedByteBuffer بيـ inherit methods من الـ java.nio.ByteBuffer superclass بتاعه، وبيـ declare كمان الـ methods دي:
MappedByteBuffer load()
بيحاول يعمل load لكل الـ mapped file content للـ memory، ده بيؤدي لسرعة أكبر في انك تـ access الملفات الكبيرة لإن الـ virtual memory manager مش بيضطر يحمل يـ load اجزاء من الملف في الـ memory لما الأجزاء دي تتطلب اثناء الـ traveling في الـ mapped buffer. ممكن الـload()متنجحش لإن الـ external programs ممكن تخلي الـ virtual memory manager يشيل اجزاء من الـ file content الي اتحمل عشان يوفرلهم مساحة لمحتواهم في ال physical memory، ده غير انها ممكن تكون مكلفة من ناحية الوقت لإنها ممكن تخلي الـ virtual memory manager يعمل I/O كتير، والـ method دي تاخد وقت عشان تخلص.boolean isLoaded()
بترجع true لما يكون كل محتوى الـ mapped file اتعمله load في ال memory، غير كده بترجع false.
لو رجعت true فغالبًا تقدر توصل لكل ال content بعمليات I/O قليلة أو من غير خالص، انما لو رجعت false فلسه ممكن يكون الـ access للـ buffer سريع والـ mapped content يكون موجود في الـ memory، فـisLoaded()بمثابة hint لحالة الـ mapped byte buffer.MappedByteBuffer force()
بتخلي الـ changes الي اتعملت على ال mapped byte buffer تتكتب في الـ permanent storage.
لما بتتعامل مع الـ mapped byte buffers لازم تنادي الـ method دي بدل الـforce()method بتاعت الـ File channel لإن الـ channel ممكن يكون unaware من الـ changes المختلفة الي اتعملت خلال الـ mapped byte buffer.
استدعاء الـ method دي ملوش تأثير على الـ
READ_ONLYو الـPRIVATEmappings.
تعالى نعمل مثال يبسط الموضوع، هنقرأ داتا من ملف، وهنعرضها قدامنا.
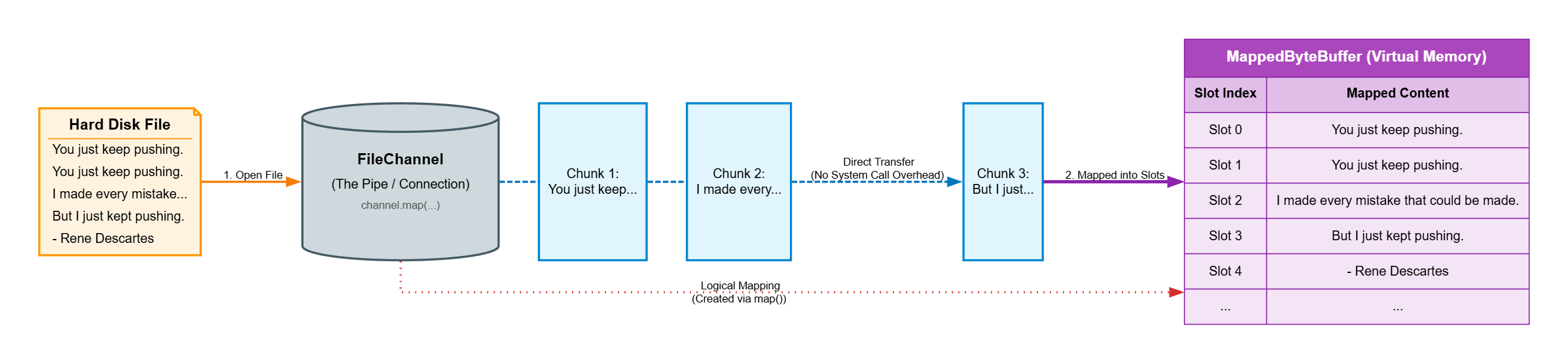
public static void main(String[] args) throws IOException {
RandomAccessFile raf = new RandomAccessFile(args[0], "rw");
FileChannel fc = raf.getChannel();
long size = fc.size();
System.out.println("size: "+size);
MappedByteBuffer mbb = fc.map(FileChannel.MapMode.READ_WRITE,0, size);
while (mbb.remaining() > 0)
System.out.print((char) mbb.get());
System.out.println();
}
الكود ده الي بيعمله اننا بنعمل RandomAccessFile على file هنباصيه للبرنامج من ال command line بـ read-write mode، بعدين هنعمل file channel على الـ file ده، هنطبع في الأول الـ size بتاعه عشان نعرف الـ file فيه داتا ولا لأ، لو الفايل مش موجود هيعمله وهيكون ال size=0.
بعدين هنعمل buffer من نوع MappedByteBuffer وهنربطه بالـ file channel الي اسمها fc، الـ map mode هيبقى READ_WRITE وهيبدأ من 0 لحد الـ size.
وزي أي buffer اتعاملنا معاه هنعمل loop طول ما لسه في داتا جواه، ونطبعها.
انا عملت فايل اسمه quote وحطيت فيه الـ text ده
You just keep pushing.
You just keep pushing.
I made every mistake that could be made.
But I just kept pushing.
- Rene Descartes
لما اشغله
java Main.java quote
الـ result هتبقى كده
size: 132
You just keep pushing.
You just keep pushing.
I made every mistake that could be made.
But I just kept pushing.
- Rene Descartes
تعالى نلعب أكتر ونشقلب ونعكس الملف، مجرد هنضيف ده
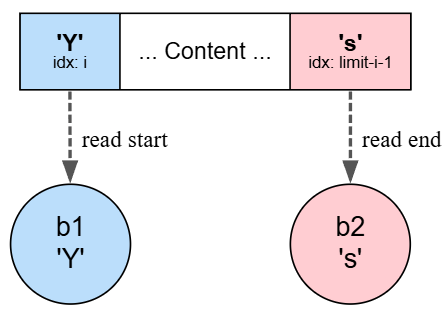
for (int i = 0; i < mbb.limit()/2; i++) {
byte b1 = mbb.get(i);
byte b2 = mbb.get(mbb.limit()-i-1);
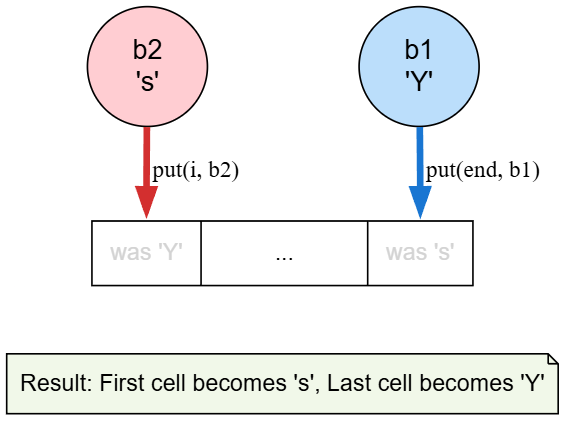
mbb.put(i,b2);
mbb.put(mbb.limit()-i-1,b1);
}
mbb.flip();
while (mbb.remaining() > 0)
System.out.print((char) mbb.get());
هنعمل loop لحد نص الملف
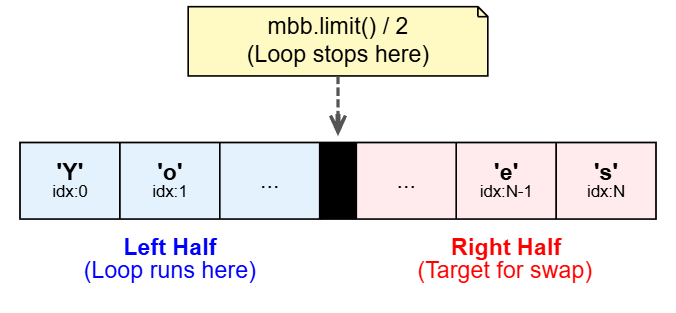
ومش هنستخدم الـ position بتاع الـ buffer هنا، هنستخدم indexes، الأول هنعمل byte اسمه b1 يشيل الـ byte من ناحية الشمال (البداية)، بعدين هنعمل byte يجيب الـ byte المقابل ليه من ناحية اليمين (النهاية) عن طريق اننا هنطرح الـ limit من ال index الحالي و -1 عشان الـ index بيبدأ من 0.
بعدين في mbb.put(i,b2) بناخد الـ byte التاني ونكتبه مكان الـ i الي احنا واقفين عليها.
و mbb.put(mbb.limit()-i-1,b1) بناخد الbyte الأول ونكتبه مكان ال byte الي ناحية اليمين، بنعمل swap يعني.
بعدين هتعمل flip عشان نقرأ من ال buffer والنتيجة هتبقى كالآتي
size: 132
You just keep pushing.
You just keep pushing.
I made every mistake that could be made.
But I just kept pushing.
- Rene Descartes
setracseD eneR -
.gnihsup tpek tsuj I tuB
.edam eb dluoc taht ekatsim yreve edam I
.gnihsup peek tsuj uoY
.gnihsup peek tsuj uoY
زي ما انتَ شايف النص تاني متشقلب ومعكوس، وهتلاقي ال file نفسه محتواه بقى متشقلب ومعكوس.
نقل الـ Bytes بين الـ Channels
أخر حاجة هنتكلم عنها هي إزاي تنقل الـ bytes بين الـ channels، عشان تحسن الـ bulk transfers.
في إتنين methods اتضافوا للـ FileChannel بيخلونا مش محتاجين لـ intermediate buffers، وهم
long transferFrom(ReadableByteChannel src, long position, long count)
دي بتنقل الـ bytes لملف الـ channel دي من الـ readable byte channel الي انت بتديهالها، الـ parameter الي اسمه src بيحدد الـ source channel والـ position بيحدد مكان البداية في الملف الي هيبدأ منه النقل، والـ count بيحدد أقصى عدد من ال bytes الي هيتم نقلها.
الـ method دي بترجع عدد الـ bytes الي اتنقلت فعلا، والي ممكن تكون 0، وبترميIllegalArgumentExceptionلما يكون في precondition على parameter مش متحقق، زي لو عامل ال position سالب مثلا وده غلط، وبترميNonReadableChannelExceptionلما الـ source channel تكون مش مفتوحة للـ read وNonWritableChannelExceptionلما الـ channel متكونش مفتوحة لل write وClosedChannelExceptionلما تكون الـ channel بتاعتنا أو الـ source channel مقفولة، وClosedByInterruptExceptionلما thread تانية تـ interrupt الـ thread الحالية والنقل شغال وده بيقفل الاتنين channels ويغير الـ interrupt status للـ thread الحالية. الـ method دي بترمي كمانIOExceptionلأي I/O error تاني.long transferTo(long position, long count, WritableByteChannel target)
دي بقى بتنقل الـ bytes من ملف الـ channel دي للـ writable byte channel الي بتديهالها، الـ position parameter بيحدد مكان البداية في الملف الي هيبدأ منه النقل، والـ count بيحدد اقصى عدد من ال bytes الي هيتم نقلها والـ target بيحدد الـ target channel.
الـ method بترجع عدد الـ bytes الي اتنقلت فعلا وبترميIllegalArgumentExceptionلما يكون في precondition على parameter مش متحقق ترميNonReadableChannelExceptionلما الـ channel دي تكون مش مفتوحة للـ read وNonWritableChannelExceptionلما الـ target channel متكونش مفتوحة لل write وClosedChannelExceptionلما تكون الـ channel بتاعتنا أو الـ target channel مقفولة وClosedByInterruptExceptionلما thread تانية تـ interrupt الـ thread الحالية والنقل شغال وده بيقفل الاتنين channels ويغير الـ interrupt status للـ thread الحالية. الـ method دي بترمي كمانIOExceptionلأي I/O error تاني.
لو بتستخدمtransferFrom()مع file channel كـ transfer source، الـ transfer بيقف عند نهاية الـ file لما الـ position + count يتخطى حجم الملف، يعني لو طلبت كمية بيانات أكبر من الي موجودة فعلا في الملف، فالبرنامج مش هيهنج أو يبعت بيانات عشوائية، فمثلا لو عندك ملف حجمه 100 بايت، وانت كنت عايز تقرأ من البايت رقم 90 ويقرأ 50 بايت، فمش هيوصل لل 140 الي هو مش موجود اصلا لان الملف 100 بس، هيقف عند ال 100 ويرجع 10 مش 50.
ده مثال إزاي تستخدم الـ channel transfer عشان تنقل محتويات ملف لملف تاني:
public static void main(String[] args) throws IOException {
try {
FileInputStream fis = new FileInputStream(args[0]);
FileChannel inChannel = fis.getChannel();
WritableByteChannel outChannel = Channels.newChannel(System.out);
inChannel.transferTo(0,inChannel.size(),outChannel);
}catch (IOException e){
System.err.println(e.getMessage());
}
}
الأول عملنا FileInputStream عشان نفتح الملف الي هنبعته في ال command line وعملنالهfile channel اسمها in channel، وعملنا WritableByteChannel اسمها outChannel على System.out عشان نبعت ال bytes للـ standard output stream وبننادي على transferTo عشان تبدأ النقل من أول بايت في الملف، وينقل عدد bytes بيساوي حجم الملف كله inChannel.size() ويحط الداتا دي في الـ outChannel.
لو شغلت ال script ده كده هتلاقيه نقل محتويات الـ quote file لـ file تاني.
java Main.java quote > quote.txt